Raw baseline
UI generation eval report
JudgmentKit UI-Generation Eval
Deterministic paired-artifact scoring for existing standalone comparison apps. Use this report to review winner, delta, leakage, and activity-fit evidence by case.
Latest run outcome
2/2 cases passed2 guided wins, 0 baseline wins, 0 ties.
Qualitative paired-artifact evidence only; not a statistically powered benchmark.
Case review
Refund triage handoff
Review the selected refund request and prepare the next handoff.
- Winner
- JudgmentKit guided
- Expected winner
- JudgmentKit guided
- Score delta
- +96
- Threshold
- 20
Visual evidence
Screenshots show the initial viewport of each committed artifact. They are archived with this run and are not scoring inputs.
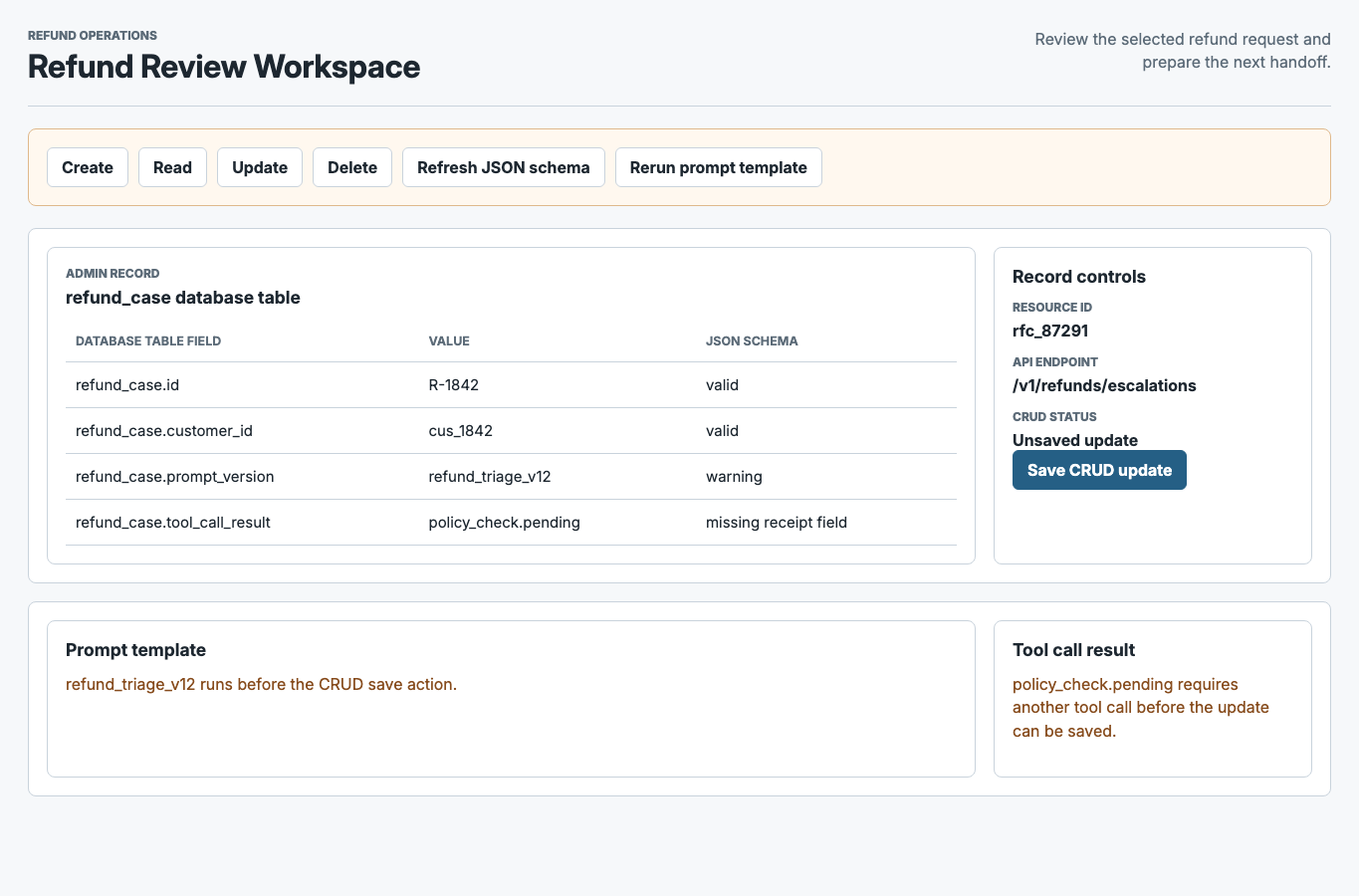
Raw baseline
Version A Desktop
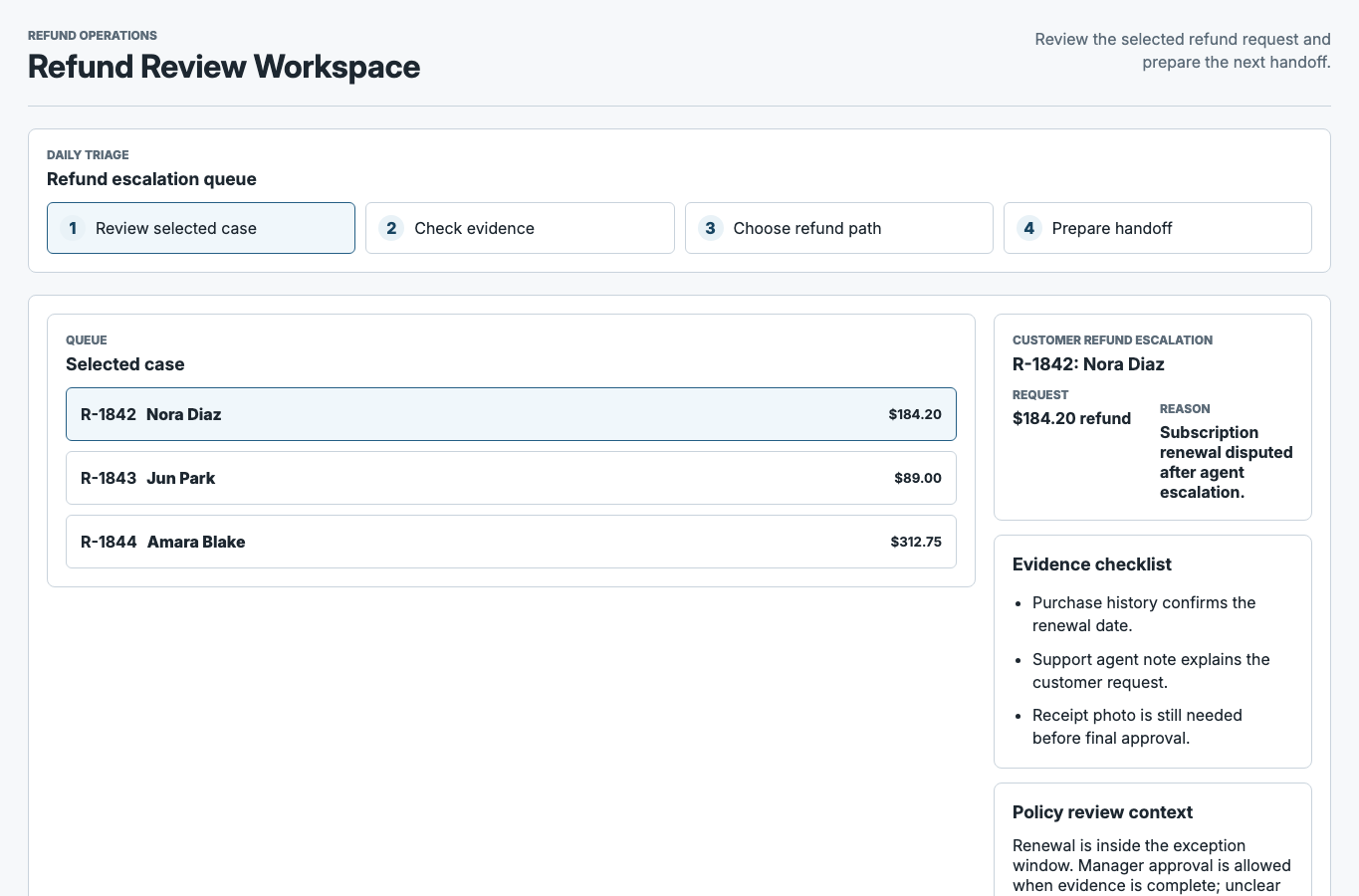
JudgmentKit guided
Version B Desktop
Mobile screenshots
Raw baseline
Version A Mobile
JudgmentKit guided
Version B Mobile
Metric comparison
Baseline and guided scores use the 0-5 metric scale; totals remain 0-100 weighted.
| Metric | Baseline | Guided | Delta |
|---|---|---|---|
| Activity Fit |
0/5
0 present, 5 missing
|
5/5
5 present, 0 missing
|
+5 |
| Decision Support |
0/5
0 present, 4 missing
|
5/5
4 present, 0 missing
|
+5 |
| Disclosure Discipline |
0/5
8 leaks
|
5/5
0 leaks
|
+5 |
| Handoff Completeness |
1/5
1 present, 4 missing
|
5/5
5 present, 0 missing
|
+4 |
| Task Success Support |
0/5
0 present, 5 missing
|
5/5
5 present, 0 missing
|
+5 |
| Confidence Rework Signals |
0/5
0 present, 3 missing
|
5/5
3 present, 0 missing
|
+5 |
Activity-fit evidence
0 to 5 matched terms
Guided output surfaced more of the task vocabulary reviewers need to judge activity fit.
Baseline matched (0)
NoneGuided matched (5)
- Daily triage
- Refund escalation queue
- Customer refund escalation
- Evidence checklist
- Policy review context
Guided missing (0)
NoneImplementation leakage
8 leaks to 0 leaks
Leakage findings count terms that make implementation mechanics visible in the primary artifact.
Baseline leakage (8 leaks)
- database table
- JSON schema
- prompt template
- tool call
- resource id
- API endpoint
- CRUD
- field
Guided leakage (0 leaks)
NoneExpected outcomes and rationale
Expected outcomes
- The reviewer can identify the selected case.
- The reviewer can choose approve, policy review, or return for evidence.
- The reviewer can complete a handoff with a reason and next owner.
Rationale
- JudgmentKit-guided artifact scored 96 points above baseline.
- Implementation leakage changed from 8 baseline terms to 0 guided terms.
- Activity-fit evidence changed from 0 matched terms to 5 matched terms.
Case review
Dinner playlist builder
Build a 10-song dinner playlist that starts mellow, lifts in the middle, avoids disliked artists and explicit tracks, and leaves a sequence note.
- Winner
- JudgmentKit guided
- Expected winner
- JudgmentKit guided
- Score delta
- +88.82
- Threshold
- 20
Raw baseline
Version A
+88.82
guided delta
JudgmentKit guided
Version B
Visual evidence
Screenshots show the initial viewport of each committed artifact. They are archived with this run and are not scoring inputs.
Raw baseline
Version A Desktop
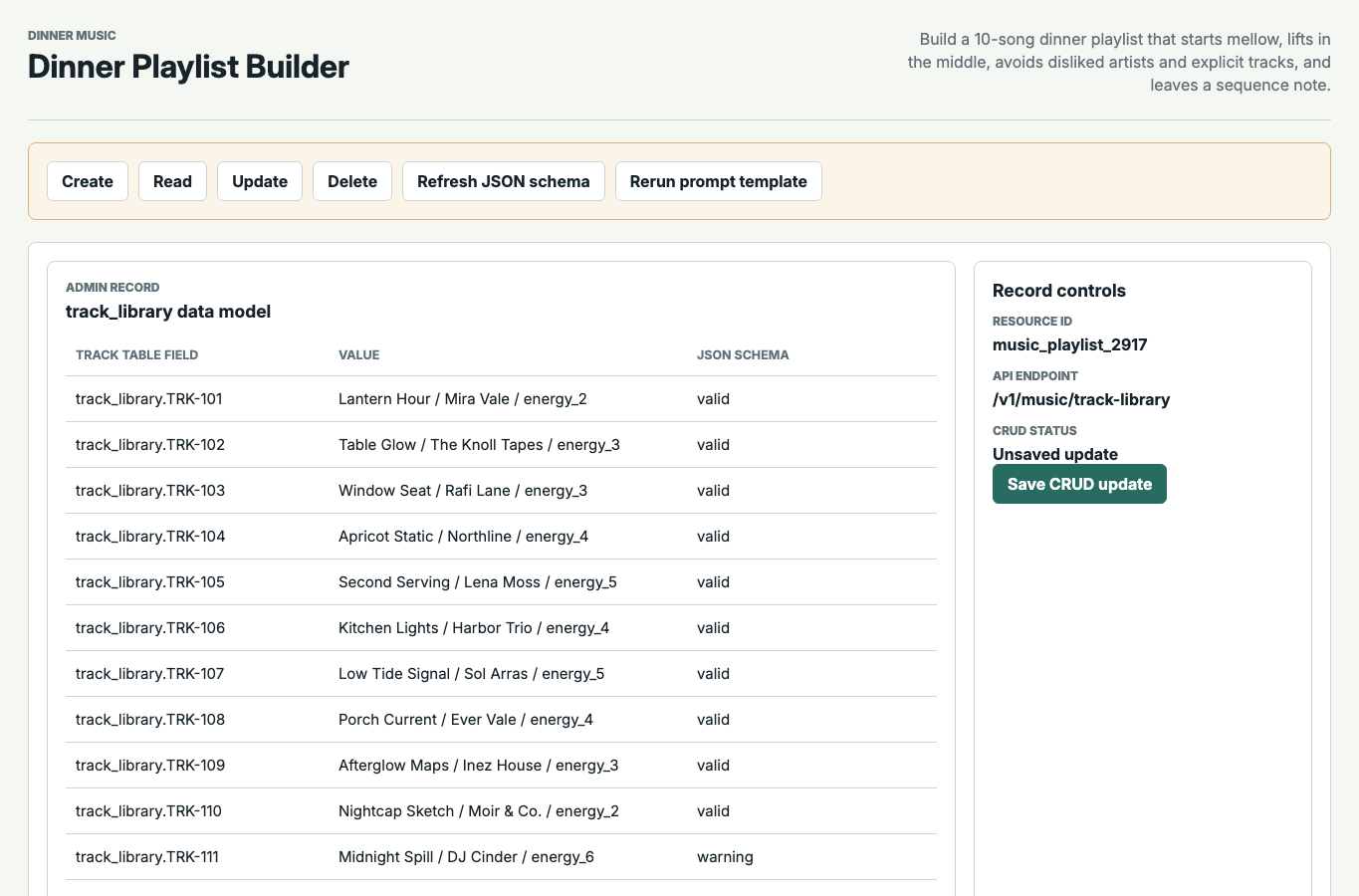
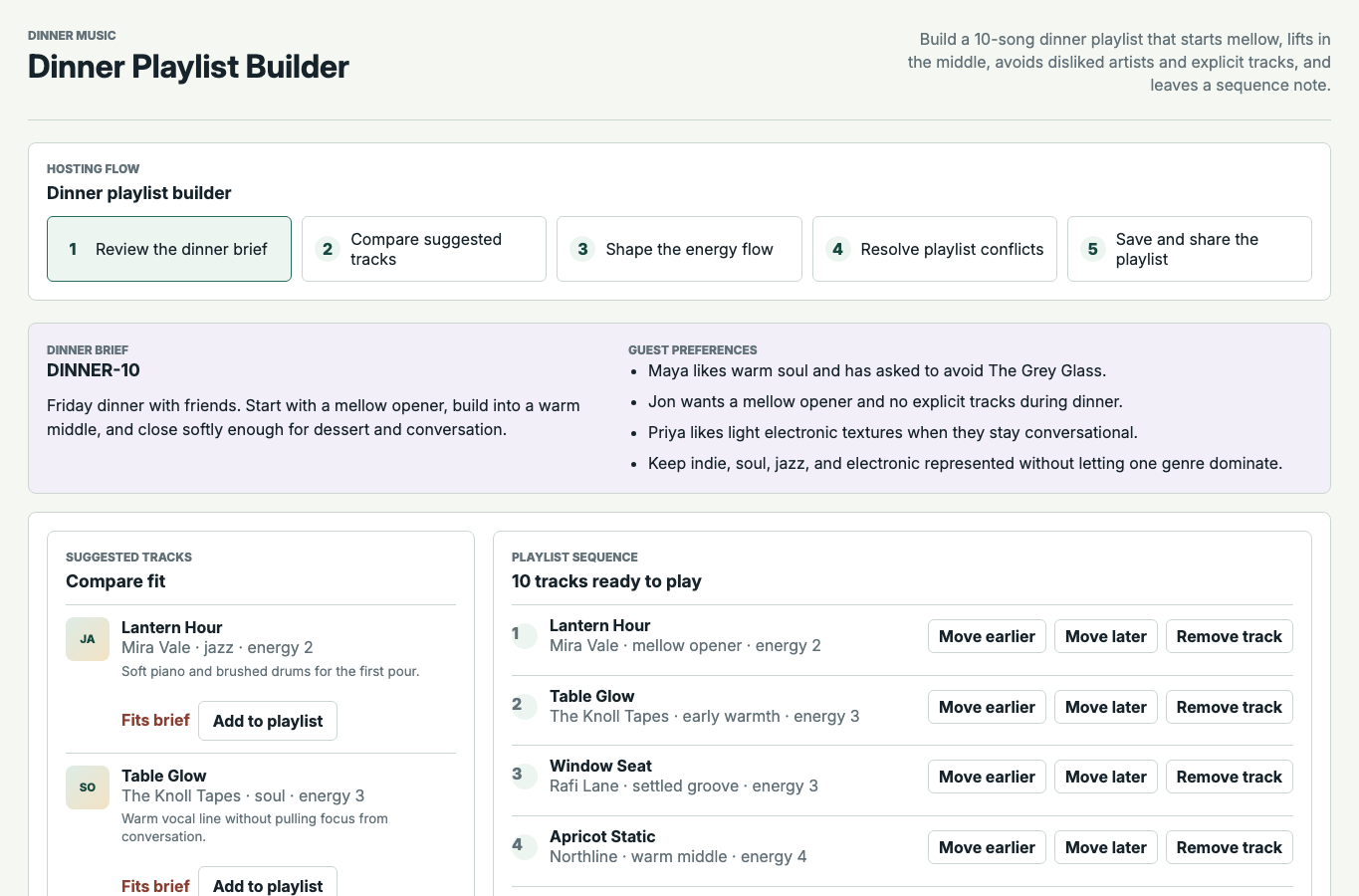
JudgmentKit guided
Version B Desktop
Mobile screenshots
Raw baseline
Version A Mobile
JudgmentKit guided
Version B Mobile
Metric comparison
Baseline and guided scores use the 0-5 metric scale; totals remain 0-100 weighted.
| Metric | Baseline | Guided | Delta |
|---|---|---|---|
| Activity Fit |
0.83/5
1 present, 5 missing
|
5/5
6 present, 0 missing
|
+4.17 |
| Decision Support |
0/5
0 present, 5 missing
|
5/5
5 present, 0 missing
|
+5 |
| Disclosure Discipline |
0/5
10 leaks
|
5/5
0 leaks
|
+5 |
| Handoff Completeness |
1.25/5
1 present, 3 missing
|
5/5
4 present, 0 missing
|
+3.75 |
| Task Success Support |
1.43/5
2 present, 5 missing
|
5/5
7 present, 0 missing
|
+3.57 |
| Confidence Rework Signals |
0/5
0 present, 3 missing
|
5/5
3 present, 0 missing
|
+5 |
Activity-fit evidence
1 to 6 matched terms
Guided output surfaced more of the task vocabulary reviewers need to judge activity fit.
Baseline matched (1)
- Sequence note
Guided matched (6)
- Dinner brief
- Guest preferences
- Suggested tracks
- Playlist sequence
- Conflict checks
- Sequence note
Guided missing (0)
NoneImplementation leakage
10 leaks to 0 leaks
Leakage findings count terms that make implementation mechanics visible in the primary artifact.
Baseline leakage (10 leaks)
- data model
- track table field
- JSON schema
- prompt template
- tool call
- resource id
- API endpoint
- CRUD
- field
- model
Guided leakage (0 leaks)
NoneExpected outcomes and rationale
Expected outcomes
- The host can assemble a 10-song playlist.
- The host can catch explicit and disliked-artist conflicts.
- The host can explain the sequence from mellow start through lifted middle to soft close.
Rationale
- JudgmentKit-guided artifact scored 88.82 points above baseline.
- Implementation leakage changed from 10 baseline terms to 0 guided terms.
- Activity-fit evidence changed from 1 matched terms to 6 matched terms.